常用的查找算法: 顺序查找,二分查找,分块查找,哈希查找,二叉树查找。
1. 顺序查找
顺序查找是最简单的查找算法,平均时间复杂度O(n);
2. 二分查找
二分查找又称折半查找,它是一种效率较高的查找方法。二分查找有两个要求:
- 1.必须采用顺序存储结构
- 2.必须按关键字大小有序排列。
|
|
二分查找时间复杂度为 O(logn)
3. 分块查找
有时候,可能会遇到这样的表:整个表中的元素未必有序,但若划分为若干块后,每一块中的所有元素均小于(或大于)其后面块中的所有元素。我们称这种为分块有序。
分块查找是折半查找和顺序查找的一种改进方法,分块查找由于只要求索引表是有序的,对块内节点没有排序要求,因此特别适合于节点动态变化的情况。
建立一个索引表,索引表中为每一块都设置–索引项,每一个索引项都包含两个内容:
- 该块的起始地址
- 该块中最大(或最小)的元素
显然,索引表是按关键字递增或递减次序排列的。如下图所示: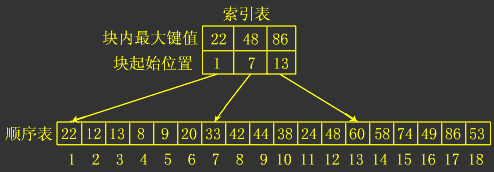
查找过程:
- 在索引表中查找,目的是找出关键所属的块的位置。这里如果索引表较大的话,可以采用折半查找。
- 进入该块中,使用简单顺序表查找算法进行关键字查找。
算法分析:
这种带索引表的分块有序表查找的时间性能取决于两步查找时间之和:第一步可以采用简单顺序查找和折半查找之一进行。第二步只能采用简单顺序查找,但由于子表的长度较原表的长度小。因此,其时间性能介于顺序查找和折半查找之间。
4. 哈希查找
哈希查找是通过计算数据元素的存储地址进行查找的一种方法。以空间换时间,时间复杂度为O(1)。哈希查找的本质是先将数据映射成它的哈希值,然后通过哈希值来进行查找操作。哈希查找的核心是构造一个哈希函数,它将原来直观、整洁的数据映射为看上去似乎是随机的一些整数。
哈希查找的操作步骤:
- 用给定的哈希函数构造哈希表;
- 根据选择的冲突处理方法解决地址冲突;
- 在哈希表的基础上执行哈希查找。
建立哈希表操作步骤:
- step1: 取数据元素的关键字key,计算其哈希函数值(地址)。若该地址对应的存储空间还没有被占用,则将该元素存入,否则执行step2解决冲突。
- step2 根据选择的冲突处理方法,计算关键字key的下一个存储地址。若下一个存储地址仍被占用,则继续执行step2,直到找到能用的存储地址为止。
哈希查找操作步骤:
- step1 对给定k值,计算哈希地址 Di=H(k);若HST为空,则查找失败;若HST=k,则查找成功;否则,执行step2(处理冲突)。
- step2 重复计算处理冲突的下一个存储地址 Dk=R(Dk-1),直到HST[Dk]为空,或HST[Dk]=k为止。若HST[Dk]=K,则查找成功,否则查找失败。
常用的计算哈希值的方法:
- ”直接定址法“。
key=value+C;这个“C”是常量。Value+C其实就是一个简单的哈希函数。
- ”直接定址法“。
- “除法取余法”。
key=value%C;解释同上。
- “除法取余法”。
- “数字分析法”。
比如有一组value1=112233,value2=112633,value3=119033,
针对这样的数我们分析数中间两个数比较波动,其他数不变。那么我们取key的值就可以是key1=22,key2=26,key3=90。
- “数字分析法”。
- “折叠法”。
- “平方取中法”。
影响哈希查找效率的一个重要因素是哈希函数本身。当两个不同的数据元素的哈希值相同时,就会发生冲突。为减少发生冲突的可能性,哈希函数应该将数据尽可能分散地映射到哈希表的每一个表项中。
解决冲突的方法有以下两种:
- 开放地址法
如果两个数据元素的哈希值相同,则在哈希表中为后插入的数据元素另外选择一个表项。当查找哈希表时,如果没有在第一个对应的哈希表项中找到符合查找要求的数据元素,程序就会继续往后查找,直到找到一个符合查找要求的数据元素,或者遇到一个空的表项。
- 开放地址法
- 链地址法
将哈希值相同的数据元素存放在一个链表中,在查找哈希表的过程中,当查找到这个链表时,必须采用线性查找方法。
- 链地址法
下面是一个示例:
|
|
参考:Link
5. 二叉树查找
二叉查找树是先对待查找的数据进行生成树,确保树的左分支的值小于右分支的值,查找的时候逐个和每个节点的父节点比较大小,查找最适合的范围。 这个算法的查找效率很高,但是如果使用这种查找方法要首先创建树。
先创建二叉排序树:
- 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
- 若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
- 任意节点的左、右子树也分别为二叉查找树;
在二叉查找树b中查找x的原理为:
- 若b是空树,则搜索失败,否则:
- 若x等于b的根节点的数据域之值,则查找成功;否则:
- 若x小于b的根节点的数据域之值,则搜索左子树;否则:
- 查找右子树。
除顺序查找处,查找算法的思路都差不多,先对数据按某种方法进行排序,然后使用相应的规则查找。